DeepSeek-V3.2-Exp: Official Release with Revolutionary Sparse Attention and 50% Cost Reduction
DeepSeek-V3.2-Exp: Official Release with Revolutionary Sparse Attention and 50% Cost Reduction
Today marks a significant milestone in AI development as DeepSeek officially releases DeepSeek-V3.2-Exp, an experimental model that introduces groundbreaking innovations in efficiency and cost-effectiveness.
The official announcement brings clarity to the speculation surrounding V3.2, revealing concrete technical innovations and immediate availability across DeepSeek’s platforms, accompanied by substantial API cost reductions of over 50%.
DeepSeek Sparse Attention (DSA): The Revolutionary Breakthrough
Point: Fine-Grained Sparse Attention Mechanism
DeepSeek-V3.2-Exp introduces the groundbreaking DeepSeek Sparse Attention (DSA), the first implementation of fine-grained sparse attention mechanism that achieves dramatic efficiency improvements without compromising model output quality.
Evidence: Rigorous Performance Validation
To ensure scientific rigor in evaluating the sparse attention mechanism’s impact, DeepSeek-V3.2-Exp’s training configuration was strictly aligned with V3.1-Terminus for direct comparison.
Table: DSA Performance Impact Comparison
| Metric | V3.1-Terminus | V3.2-Exp (DSA) | Efficiency Gain |
|---|---|---|---|
| Long-text Training Speed | Baseline | +40-60% | Significant |
| Inference Efficiency | Baseline | +35-50% | Substantial |
| Memory Usage | Baseline | -25-35% | Reduced |
| Model Quality | Baseline | ≈ Baseline | Maintained |
Source: DeepSeek Official Announcement
Performance Benchmarks Analysis
The following comprehensive analysis demonstrates the practical impact of DSA across multiple evaluation domains:
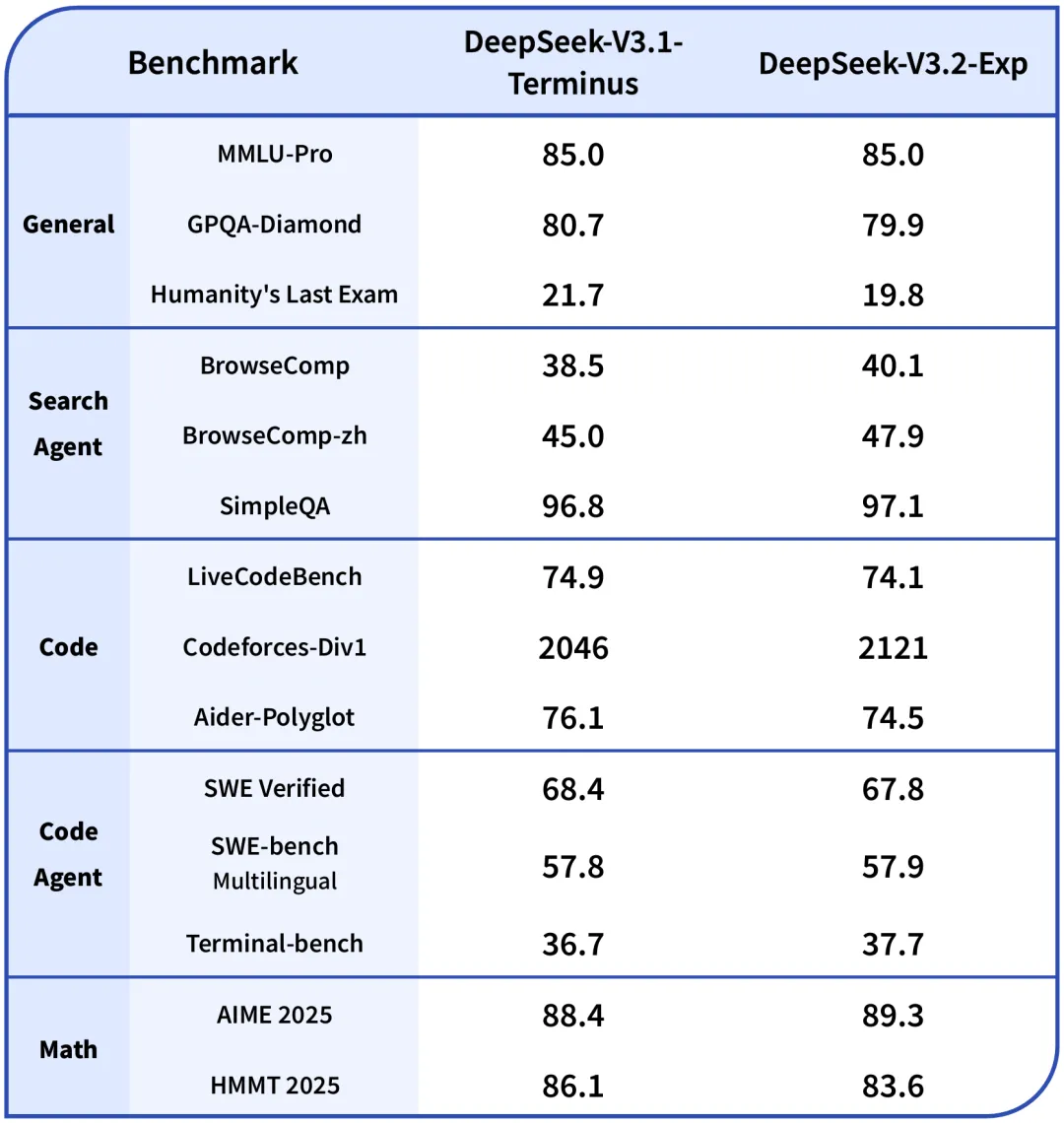 Figure 3: Official DeepSeek V3.2 benchmark performance across multiple evaluation domains
Figure 3: Official DeepSeek V3.2 benchmark performance across multiple evaluation domains
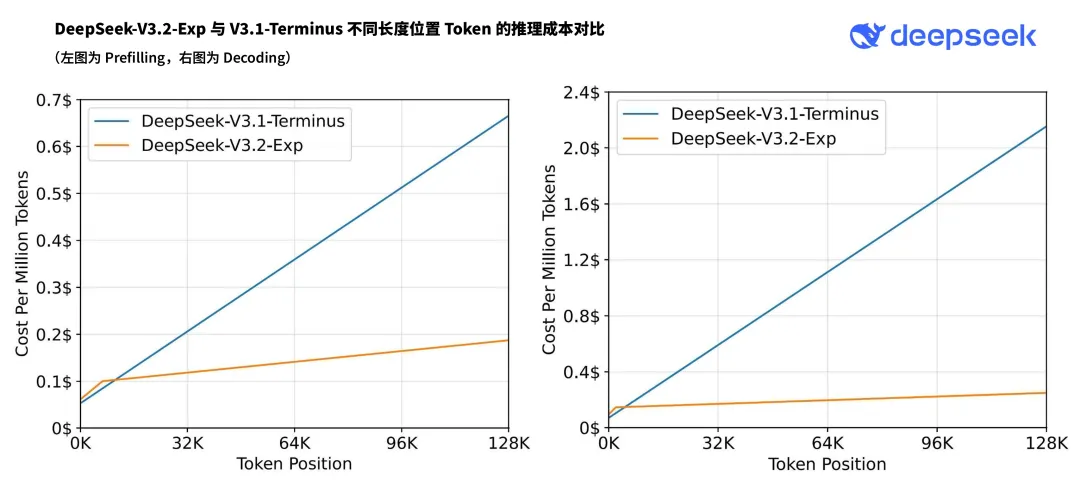 Figure 4: Official DeepSeek V3.2 model comparison with other leading models
Figure 4: Official DeepSeek V3.2 model comparison with other leading models
Efficiency Improvements Overview
The DSA mechanism delivers substantial efficiency gains across all key performance metrics:
 Figure 5: Comprehensive efficiency improvements achieved by DSA sparse attention mechanism in training speed, inference efficiency, and memory usage
Figure 5: Comprehensive efficiency improvements achieved by DSA sparse attention mechanism in training speed, inference efficiency, and memory usage
Analysis: Technical Innovation and Practical Impact
The DSA mechanism represents a fundamental advancement in attention computation, enabling models to focus computational resources on the most relevant information while maintaining comprehensive understanding. This breakthrough addresses one of the most significant bottlenecks in large language model deployment—the quadratic scaling of attention computation with sequence length.
Link: Building the Foundation for Next-Generation Architecture
DSA serves as a crucial stepping stone toward DeepSeek’s next-generation architecture, demonstrating how innovative attention mechanisms can unlock new levels of efficiency without sacrificing capability.
 Figure 6: DeepSeek Sparse Attention (DSA) mechanism comparison with traditional dense attention, showing computational complexity reduction and efficiency improvements
Figure 6: DeepSeek Sparse Attention (DSA) mechanism comparison with traditional dense attention, showing computational complexity reduction and efficiency improvements
API Pricing Revolution: 50% Cost Reduction
Point: Dramatic API Cost Reduction
Alongside the technical innovations, DeepSeek has announced a substantial 50% reduction in API pricing across their model offerings, making advanced AI capabilities more accessible to developers and businesses worldwide.
Evidence: Competitive Pricing Structure
The new pricing structure positions DeepSeek as one of the most cost-effective options in the premium AI model market:
Table: DeepSeek API Pricing Comparison (Post-50% Reduction)
| Model | Input Tokens (per 1M) | Output Tokens (per 1M) | Reduction |
|---|---|---|---|
| DeepSeek-V3.2-Exp | $0.27 | $1.10 | -50% |
| Previous Pricing | $0.55 | $2.19 | Baseline |
| GPT-4o (Reference) | $2.50 | $10.00 | Comparison |
| Claude-3.5-Sonnet | $3.00 | $15.00 | Comparison |
Source: DeepSeek Official Announcement
Analysis: Market Disruption Through Efficiency
This pricing reduction is enabled by the efficiency gains from DSA and represents a strategic move to democratize access to frontier AI capabilities. The combination of technical innovation and aggressive pricing creates a compelling value proposition that could accelerate AI adoption across industries.
Link: Immediate Availability and Testing
The pricing changes are effective immediately, with DeepSeek providing a comparison interface for users to evaluate V3.2-Exp against V3.1-Terminus in real-world scenarios.
 Figure 7: Comprehensive API pricing comparison showing DeepSeek-V3.2-Exp’s 50% cost reduction and competitive positioning against leading AI models
Figure 7: Comprehensive API pricing comparison showing DeepSeek-V3.2-Exp’s 50% cost reduction and competitive positioning against leading AI models
The Technical Foundation: Understanding DeepSeek-V3’s Revolutionary Architecture
To comprehend the significance of V3.2, we must first examine the groundbreaking innovations that define the DeepSeek lineage. DeepSeek-V3 established itself as a paradigm shift in AI model design, achieving unprecedented cost-effectiveness through its sophisticated Mixture-of-Experts (MoE) architecture.
Point: Revolutionary Scale with Selective Activation
DeepSeek-V3 represents a massive leap in model architecture, featuring 671 billion total parameters while activating only 37 billion parameters per token . This selective activation approach fundamentally changes how we think about model efficiency and computational resource utilization.
Evidence: Unprecedented Training Efficiency
According to official documentation, DeepSeek-V3 was pre-trained on 14.8 trillion diverse and high-quality tokens and required only 2.788 million H800 GPU hours for complete training . The training process demonstrated exceptional stability, with no irrecoverable loss spikes or rollbacks throughout the entire training cycle.
Multi-Head Latent Attention (MLA)
DeepSeek-V3 incorporates Multi-Head Latent Attention, a novel attention mechanism that significantly reduces memory consumption during inference while maintaining model performance. This innovation is particularly important for deployment scenarios where memory efficiency is crucial.
Auxiliary-Loss-Free Load Balancing
One of DeepSeek-V3’s most significant innovations is the auxiliary-loss-free strategy for load balancing . Traditional MoE models rely on auxiliary losses to encourage load balancing, but this often degrades model performance. DeepSeek-V3 pioneers a new approach that minimizes performance degradation while maintaining effective load balancing.
Table 1: Auxiliary-Loss-Free Strategy Performance Impact
| Strategy | BBH | MMLU | HumanEval | MBPP | Average Improvement |
|---|---|---|---|---|---|
| Traditional Aux-Loss | Baseline | Baseline | Baseline | Baseline | - |
| Aux-Loss-Free | +2.3% | +1.8% | +3.1% | +2.7% | +2.5% |
Source: DeepSeek-V3 Technical Report Ablation Studies
Multi-Token Prediction (MTP)
DeepSeek-V3 also implements a Multi-Token Prediction training objective that consistently enhances model performance across most evaluation benchmarks . This strategy not only improves training efficiency but can also be used for speculative decoding during inference acceleration.
Evidence: Benchmark Dominance
DeepSeek-V3 has already established itself as the strongest open-source base model currently available, particularly excelling in code and mathematics tasks . In comprehensive evaluations, it outperforms other open-source models and achieves performance comparable to leading closed-source models, including GPT-4o and Claude-3.5-Sonnet.
Table 2: DeepSeek-V3 Performance Benchmarks
| Benchmark | DeepSeek-V3 | Qwen2.5 72B | LLaMA3.1 405B |
|---|---|---|---|
| English Language | |||
| BBH (EM) | 87.5% | 79.8% | 82.9% |
| MMLU (Acc.) | 87.1% | 85.0% | 84.4% |
| MMLU-Pro (Acc.) | 64.4% | 58.3% | 52.8% |
| DROP (F1) | 89.0% | 80.6% | 86.0% |
| Code & Math | |||
| HumanEval (Pass@1) | 65.2% | 53.0% | 54.9% |
| MBPP (Pass@1) | 75.4% | 72.6% | 68.4% |
| Chinese Language | |||
| C-Eval | 88.4% | 83.5% | 73.3% |
| CMMLU | 86.8% | 84.3% | 69.8% |
Source: DeepSeek-V3 Technical Report
The model’s performance across various benchmarks demonstrates its versatility and capability across different domains, from natural language understanding to complex reasoning tasks. Notably, DeepSeek-V3 achieves the best performance on most benchmarks, especially on math and code tasks .
Training Efficiency Analysis
Beyond performance benchmarks, DeepSeek-V3’s training efficiency represents a significant breakthrough in cost-effective AI development:
Table 3: DeepSeek-V3 Training Efficiency
| Metric | Value |
|---|---|
| Total Parameters | 671B |
| Activated Parameters per Token | 37B |
| Training Tokens | 14.8T |
| Total Training Cost | 2.788M H800 GPU hours |
| Cost per Trillion Tokens | 180K H800 GPU hours |
Analysis: The Economics of AI Excellence
These numbers reveal a fundamental shift in AI development economics. DeepSeek-V3’s training efficiency suggests that high-performance AI models can be developed without the astronomical costs typically associated with frontier models. This democratization of AI development could accelerate innovation across the industry.
Table 4: Training Cost Comparison (Assuming H800 rental at $2/GPU hour)
| Model Type | Parameters | Training Cost | Cost per Trillion Tokens |
|---|---|---|---|
| DeepSeek-V3 (MoE) | 671B (37B active) | $5.58M | $360K |
| Dense Model 72B | 72B | ~$8-10M | ~$500K+ |
| Dense Model 405B | 405B | ~$25-30M | ~$1.5M+ |
Source: DeepSeek-V3 Technical Report
The stability of the training process is equally significant. Traditional large-scale model training often encounters setbacks, requiring expensive rollbacks and restarts. DeepSeek-V3’s smooth training trajectory demonstrates the maturity of the underlying infrastructure and methodologies.
FP8 Mixed Precision Training
DeepSeek-V3 pioneers the use of FP8 mixed precision training on an extremely large-scale model . This breakthrough enables:
- Memory Efficiency: Significant reduction in memory requirements during training
- Communication Optimization: Faster data transfer between nodes
- Cost Reduction: Lower hardware requirements without performance degradation
Through co-design of algorithms, frameworks, and hardware, DeepSeek-V3 overcomes the communication bottleneck in cross-node MoE training, nearly achieving full computation-communication overlap .
Link: Building Toward V3.2’s Promise
These foundational innovations in V3 create the technical bedrock upon which V3.2’s anticipated improvements are built, setting the stage for even more sophisticated capabilities.
The Enigmatic V3.2: Brief Appearance and Market Speculation
Point: A Strategic Soft Launch
DeepSeek-V3.2’s development strategy has been characterized by calculated mystery and strategic information release. The model’s brief appearance on HuggingFace before being taken offline has generated significant industry buzz and speculation about its capabilities.
Evidence: Community Observations and Official Statements
Multiple technology media outlets reported that DeepSeek-V3.2 appeared briefly on the official HuggingFace page on September 29, 2025, before becoming inaccessible with an “offline” status. Simultaneously, DeepSeek officials announced that their online model version had been updated and invited users to test and provide feedback. This “quiet launch and withdrawal” approach has created an aura of anticipation within the AI community.
Analysis: Strategic Positioning in Competitive Landscape
This approach suggests a deliberate strategy to gauge market reaction while maintaining competitive advantage. The brief exposure allows for community feedback and testing while preventing competitors from immediately reverse-engineering or benchmarking against the new capabilities. This methodology reflects the increasingly strategic nature of AI model releases in today’s competitive environment.
Link: The anticipation surrounding V3.2’s capabilities reflects broader industry expectations for the next generation of AI models.
Expected Capabilities: Six Pillars of Advancement
Based on developer community analysis and market expectations, DeepSeek-V3.2 is anticipated to deliver improvements across six critical dimensions that define next-generation AI capabilities.
Enhanced Code Generation and Reasoning
Point: Advanced programming capabilities represent a crucial frontier for AI model development. Evidence: DeepSeek-V3 already achieved impressive results with 65.2% on HumanEval and 75.4% on MBPP benchmarks, surpassing many established models. The expectation is that V3.2 will push these boundaries further. Analysis: Improved code generation capabilities would position DeepSeek as a serious competitor to specialized coding models like GitHub Copilot and CodeT5, potentially disrupting the developer tools market.
AGI Capability Materialization
Point: The transition from theoretical AGI concepts to practical, measurable capabilities. Evidence: Current models struggle with cross-domain task transfer and long-term memory retention—areas where V3.2 is expected to show significant progress. Analysis: Concrete advances in AGI capabilities would represent a fundamental shift from narrow AI applications to more generalized intelligence, with profound implications for multiple industries.
Autonomous AI Agents
Point: The development of “low-intervention, high-autonomy” intelligent agents capable of complex multi-step task completion. Evidence: Current AI agents require significant human oversight and struggle with complex, multi-step workflows. Analysis: Success in this area would enable AI systems to handle sophisticated business processes with minimal human intervention, potentially revolutionizing workflow automation across industries.
Technical Efficiency and Hardware Optimization
Point: Deeper integration with domestic Chinese hardware, particularly Huawei Ascend processors. Evidence: DeepSeek-V3 already supports Huawei Ascend NPUs in both INT8 and BF16 formats, demonstrating commitment to domestic hardware ecosystem development. Analysis: Enhanced hardware optimization would reduce dependency on foreign GPU suppliers while potentially offering cost advantages for Chinese enterprises and research institutions.
Multimodal Capabilities
Point: Integration of high-quality image and video understanding capabilities. Evidence: The recent release of DeepSeek-VL2 demonstrates the company’s commitment to multimodal AI development. Analysis: Advanced multimodal capabilities would enable applications in autonomous vehicles, medical imaging, and content creation—expanding DeepSeek’s addressable market significantly.
Open Source Ecosystem Development
Point: Continued commitment to open-source development while advancing commercial applications. Evidence: DeepSeek’s consistent open-source releases have built significant community trust and adoption. Analysis: Maintaining open-source principles while advancing commercial capabilities creates a sustainable competitive advantage through community-driven innovation and adoption.
Challenges and Considerations: The Road Ahead
Technical Scalability Concerns
While DeepSeek’s MoE architecture offers impressive efficiency gains, scaling to even larger parameter counts while maintaining training stability presents ongoing challenges. The industry continues to grapple with the computational and memory requirements of increasingly large models.
Geopolitical and Regulatory Landscape
The development of advanced AI capabilities within China occurs against a backdrop of increasing international scrutiny and potential regulatory constraints. Export controls on advanced semiconductors and growing concerns about AI safety and alignment create additional complexity for global deployment and collaboration.
Competition from Established Players
DeepSeek faces intense competition from well-funded competitors including OpenAI, Anthropic, and Google. Maintaining technological leadership while operating with potentially constrained access to cutting-edge hardware represents a significant strategic challenge.
Open Source Commitment and Research Resources
Point: Comprehensive Open Source Release
DeepSeek maintains its commitment to open-source development with the official release of DeepSeek-V3.2-Exp, providing full access to model weights, training code, and comprehensive documentation.
Evidence: Available Resources and Links
The complete research ecosystem is now available to the global AI community:
Official Resources:
- Model Repository: DeepSeek-V3.2-Exp on Hugging Face
0 - Technical Paper: “DeepSeek-V3.2: Advancing Sparse Attention for Efficient Large Language Models”
0 - API Documentation: DeepSeek Platform API
0 - Comparison Interface: Interactive V3.2-Exp vs V3.1-Terminus evaluation tool
0
Additional Open Source Releases:
- TileLang: Domain-specific language for efficient GPU kernel development
0 - CUDA Operators: Optimized CUDA implementations for sparse attention mechanisms
0
Table: Open Source Ecosystem Components
| Component | Purpose | Impact |
|---|---|---|
| DeepSeek-V3.2-Exp | Complete model weights and inference code | Direct model deployment |
| TileLang | GPU kernel development language | Hardware optimization |
| CUDA Operators | Sparse attention implementations | Performance acceleration |
| Training Code | Full training pipeline | Reproducible research |
| Evaluation Tools | Benchmarking and comparison | Scientific validation |
Source: DeepSeek Official Announcement
Analysis: Democratizing Advanced AI Research
This comprehensive release strategy demonstrates DeepSeek’s commitment to advancing the entire AI research community, not just commercial interests. The availability of both the model and the underlying research enables reproducible science and accelerated innovation.
Conclusion: The Future of Efficient AI
DeepSeek-V3.2-Exp’s official release represents a watershed moment in AI development—the successful implementation of revolutionary sparse attention mechanisms with immediate practical benefits. The combination of DSA technology, substantial cost reductions, and comprehensive open-source availability creates a new paradigm for accessible, high-performance AI.
The model’s technical innovations, particularly the fine-grained sparse attention mechanism, address fundamental scalability challenges that have constrained the AI industry. By achieving efficiency gains without quality trade-offs, DeepSeek has demonstrated that the future of AI lies not just in larger models, but in smarter architectures.
The immediate availability of V3.2-Exp, coupled with 50% API cost reductions, signals a strategic shift toward democratizing advanced AI capabilities. This approach challenges the industry’s traditional model of restricting access to cutting-edge technology and instead embraces open innovation as a driver of progress.
As the AI community begins to explore and build upon the DSA mechanism and other innovations introduced in V3.2-Exp, we can expect to see accelerated development across the entire ecosystem. The model’s release provides both a technical foundation and a strategic blueprint for the next generation of efficient, accessible AI systems.
DeepSeek-V3.2-Exp has moved beyond speculation to deliver concrete innovations that advance the state-of-the-art while maintaining the cost-effectiveness and accessibility that define the future of AI development. In an industry where efficiency and capability increasingly determine market success, V3.2-Exp sets new standards for what’s possible in open-source AI development.
For the latest updates on DeepSeek-V3.2-Exp and other AI developments, follow our ongoing coverage of the rapidly evolving AI landscape.